|
|
||
Radoslaw Oldakowski
November 2006
SemMF is a flexible framework for calculating semantic similarity between objects that are represented as arbitrary RDF graphs. The framework allows taxonomic and non-taxonomic concept matching techniques to be applied to selected object properties. Moreover, new concept matchers are easily integrated into SemMF by implementing a simple interface, thus making it applicable in a wide range of different use case scenarios.
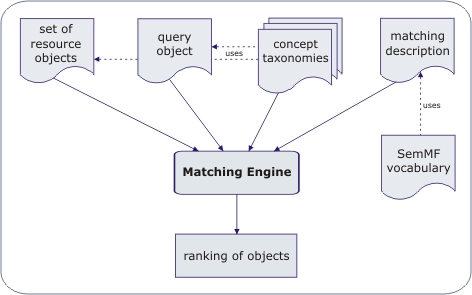
The Matching Engine takes as input a query object and a collection of resource objects to be matched against the query object. Both are represented in RDF and may utilize different schema vocabularies. If they use concepts from a common taxonomy, an RDFS or OWL representation of this taxonomy has to be provided.
SemMF Engine is implemented in Java utilizing Jena2 Semantic Web Framework for accessing and querying of resource and query graphs as well as the underlying taxonomies.
In most cases not every object property is relevant for the similarity computation. For example, an object representing a certain product may contain manufacturer's phone number which may be irrelevant for comparing product's characteristics with customer's preferences (query object). Thus, each relevant property in the query RDF graph must be explicitly specified and mapped to the semantically corresponding property (i.e. holding the same kind of information, e.g. price information) in a resource RDF graph. Each mapping is assigned a concept matcher implementing a certain matching technique.
In a matching description the importance of each object property can be specified by assigning it a certain weight . Moreover, properties to be matched can be grouped into thematic clusters, for example all properties describing technical specification of a product. The property clustering enables to sort the matching result by cluster similarities. The matching description is represented in RDF using SemMF vocabulary provided with the framework.
Inside each thematic cluster the Engine calculates the similarity between each query property and the corresponding resource property. These similarities are multiplied by the indicated weights and summed up yielding the cluster similarity. All cluster similarities, in turn, multiplied by the specified cluster weights yield the object similarity.
However, if for a given query property value there is more than one semantically corresponding resource property value (e.g. a product may be available in different colors) the Engine chooses the one with the highest similarity.
The output of the Matching Engine is a ranking of objects by their similarity values. The Engine also provides a detailed description of the matching process (i.e. object property values, similarity values for all clusters and for each single object property within a cluster, associated weights, etc.) which can be used to generate explanations for the calculated object similarity.
see next: Implemented Matchers